
Introduction: The Promise of Olink Proteomics in Cancer Research
In many research labs, identifying reliable protein biomarkers for oncology remains a major bottleneck. Traditional proteomics approaches often lack the sensitivity to detect low-abundance cytokines or immune signaling molecules in serum or plasma. Olink proteomics analysis, especially with its cytokine panels and high-plex serum proteomics, offers new power for deep protein profiling without requiring large sample volumes or sacrificing specificity.
With Olink Cytokine Panels and the broader Olink serum proteomics platforms, researchers can uncover molecular changes years before overt phenotypes emerge. For example, in a recent study using the Olink Explore-3072 platform, plasma samples collected 1-3 years before lung cancer diagnosis revealed ~240 proteins that differed in pre-disease cases vs controls. Predictive models built from those proteins yielded area under the curve (AUC) scores between 0.76 and 0.90.
In this article, we'll explore advanced applications of Olink proteomics in non-clinical oncology research: early detection signatures, immune profiling via cytokines, predictive biomarkers of treatment response, and insights from large longitudinal cohorts. The goal: equip your biotech, pharma R&D, or university team to leverage these tools to generate robust biomarker hypotheses.
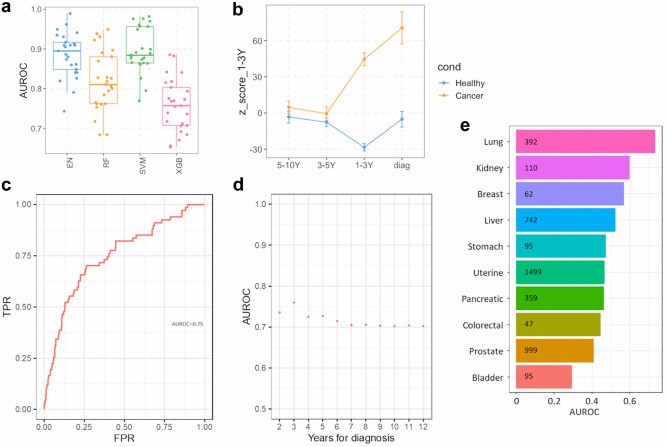 Fig. 1 Circulating plasma proteins prediction of future lung cancer.
Fig. 1 Circulating plasma proteins prediction of future lung cancer.
Key Technologies Behind Olink: Beyond Traditional Proteomics
Proteomic discovery in oncology demands high sensitivity, multiplexing, and consistency. Olink's technologies deliver on these needs, especially when studying low-abundance proteins like cytokines in serum. Below are core elements that set Olink apart, followed by considerations when choosing panels.
Core Advantages of Olink Platforms
Proximity Extension Assay (PEA) Sensitivity
Olink uses dual-antibody binding plus DNA oligonucleotide extension to amplify the signal. This enables detection of proteins in the femtomolar to low picomolar range, often below the detection limits of ELISA or standard mass spectrometry.
High Multiplexing & Small Sample Volume
Olink's Explore-3072 library, for example, profiles ~2,900 proteins across 8 modular panels, each with ~384 assays. All that from as little as 1-6 µL of plasma or serum.
Robust Quantitation & Biological Relevance
Relative quantitation via NPX (Normalized Protein eXpression) units ensures comparability across samples. The panels include many secreted proteins, immunomodulatory cytokines, organ-leak proteins, and exploratory biomarkers for oncology pathways.
Considerations When Choosing Olink Panels & Workflows
Panel Type vs Breadth of Discovery
If your goal is hypothesis generation, broad panels (e.g., Explore-3072) give coverage of secreted, immunologic, and oncology-relevant biomarkers. For focused studies (e.g., immune profiling), cytokine or inflammation panels may suffice.
Sample Preanalytic Variables
Serum/plasma handling, haemolysis, storage time, and freeze-thaw cycles all impact sensitive detection. In the lung cancer study above, over 1,100 proteins were excluded due to haemolysis correlation.
Data Analysis Strategy
Feature selection (e.g., bootstrapping), controlling confounders (age, smoking history, comorbidity), and external validation (e.g., UK Biobank) are critical to avoid overfitting. The lung cancer example used multiple machine learning algorithms and external data for validation.
Section 3: Application in Oncology: Early Detection & Diagnostic Signatures
Early detection of cancer through protein signatures can shift research-use studies from retrospective case-control toward prospective risk prediction. Olink proteomics, especially when applied to serum or plasma, has yielded several high-accuracy signatures mapping both to imminent disease and long-term risk. Below are representative examples and best practices.
Case Study: Lung Cancer Prediction from Pre-Diagnosis Samples
In the Liverpool Lung Project (Davies, Sato, et al., 2023), scientists profiled ~2,941 plasma proteins using the Olink Explore-3072 platform in 496 samples. Among those, 131 were collected 1-10 years before lung cancer diagnosis, 237 were matched controls, and 90 were longitudinal samples. After removing >1,000 proteins affected by haemolysis, a model was built with bootstrap feature selection. For samples 1-3 years pre-diagnosis, ~240 proteins differed significantly between cases and controls. Models built on those proteins achieved an area under the curve (AUC) between 0.76 and 0.90.
External validation in UK Biobank for 1-3 year pre-diagnosis gave AUC ≈ 0.75; for 1-5 years, AUC dropped somewhat but remained statistically meaningful (~0.69).
This example demonstrates that Olink serum proteomics (via Explore-3072) can detect both "risk-associated" proteins (long before overt disease) and "imminent disease" signals (just before diagnosis).
Case Study: Ovarian Cancer Diagnostic Signature
Enroth et al., 2019 discovered and validated an 11-protein signature plus age for ovarian cancer using multiple Olink Target 96 panels. They profiled ~593 plasma proteins in three cohorts (cancer patients vs controls). The final custom PEA panel, reporting in absolute concentrations, discriminated ovarian cancer (stage I-IV) from benign tumors with an AUC ~0.94, sensitivity 0.85, specificity 0.93.
Another Olink-based study measured 92 cancer-related proteins in serum from ovarian cancer vs healthy controls using the Oncology II panel. They found 52 proteins significantly different, with many novel potential markers. Combining CA125 with additional proteins increased sensitivity and specificity over CA125 alone.
Patterns & Lessons from Early Detection Studies
From comparing these studies, some consistent observations emerge:
Longitudinal vs Cross-Sectional Sampling Matters: Pre-diagnostic samples (collected before the disease is known) often reveal different proteins than cross-sectional comparisons. Signatures valid in one time window may degrade or change in another. (Lung cancer example)
Combining Biomarkers Outperforms Single Markers: Proteins combined in panels consistently outperform individual markers like CA125 (ovarian cancer) or smoking status (lung cancer). Multivariate models tend to retain robustness when validated in independent cohorts.
Absolute Quantification Adds Value: Panels that move from relative measures (NPX) to absolute concentration (e.g. custom PEA panels) help in comparability and in moving toward translational research.
To deepen understanding of diagnostic and signature-based research:
For foundational technology, see Introduction to Olink Proteomics: What You Need to Know.
For a detailed case study of cancer biomarker development, link toCase Study: Using Olink Proteomics to Investigate Cancer Biomarkers.
For insights from large, population-scale studies, check Olink Proteomics for Large-Scale Population Studies: A Success Story.
Immune / Cytokine Profiles and Tumor Microenvironment Insights
Profiling immune mediators in the tumor microenvironment (TME) via cytokine panels gives researchers a window into immune activation, suppression, and signalling dynamics. Olink Cytokine Panels enable multiplexed measurement of dozens of key cytokines, growth factors, and chemokines. This section highlights how these profiles inform non-clinical oncology research: which signatures correlate with immune phenotypes, how aging or tissue context alters cytokines, and real-world examples using Olink.
Key Findings from Cytokine Profiling in Tumor Microenvironment Studies
Correlates of Immune Activity vs Resistance
In the NEOSARCOMICS study of undifferentiated pleomorphic sarcoma, plasma proteomic profiling using Olink revealed that non-responders to neoadjuvant chemotherapy had elevated baseline immune-pathway signatures and specific cytokines compared to responders. (Vibert et al., NEOSARCOMICS)
The immune cell infiltration (e.g. CD8+ T cells, myeloid markers) in the TME correlated with these cytokine measurements.
Tissue Context Differences
A recent study comparing tumour, paired para-tumour ("para-carcinoma") and distant normal intestinal tissue in colorectal cancer (CRC) patients (n≈52) quantified 92 oncology-relevant proteins using an Olink panel. Significant differences in cytokines and other immune modulators emerged when comparing tumour vs normal tissue. This helps characterize how the immune/TME signalling differs by spatial context.
Effects of Aging in Murine Models
In mouse models, researchers used the Olink Target 48 Mouse Cytokine Panel to evaluate how aging alters immune cell populations and cytokine expression within the TME. The aged microenvironment showed reduced recruitment of certain effector T cells, altered cytokine gradients, and shifts in immunoregulatory proteins. These findings help non-clinical labs understand baseline variation in animal models.
What This Means for Biomarker Discovery & TME Modelling
From the examples above, several practical lessons emerge:
Cytokine/Immune Signatures Reflect Both Systemic and Local TME Features
Plasma cytokines can mirror immune cell infiltration in tumour tissue (as in NEOSARCOMICS). But tissue-based cytokine and protein measurement (e.g. tumour vs distant normal) can pinpoint local regulatory factors. Combining both gives a fuller picture.
Panel Choice & Sample Type Are Critical
If your study aims to profile immune suppression or immune activation locally, a tissue panel or tumour microenvironment-adapted panel is preferred. For systemic immune signatures (e.g. in pretreatment plasma), a cytokine panel in serum/plasma works. Olink Cytokine Panels (human or mouse), or broader panels with immune modules, allow this flexibility.
Accounting for Confounders
Aging, tissue location, comorbid inflammation, and sample handling influence cytokine levels. In mouse models, age was a major variable. In human studies, location (tumour vs para-tumour) or proximity to necrosis etc. matter. Proper experimental design (matched controls, spatial sampling) is essential.
Prognostic & Predictive Biomarkers: Treatment Response & Therapy Stratification
Moving beyond detection, Olink proteomics helps researchers predict how biological systems will respond to interventions, stratify subjects, and monitor changes over time. Below are documented studies, strategies, and recommendations for using Olink in predictive / prognostic biomarker discovery in oncology research (non-clinical).
Recent Case Studies
Neoadjuvant PD-1 Blockade in Head and Neck SCC
In a study of 50 patients with head and neck squamous cell carcinoma, baseline plasma cytokine panels (Olink 92-plex), combined with CyTOF immune profiling, helped distinguish responders vs non-responders to PD-1 inhibitor + chemotherapy. Key proteins (e.g. IL-5, MMP7) and immune cell subsets (central memory CD8+ T cells) contributed to a model with AUC ≈ 0.92. (Zhang et al., 2025. PMID: Translational Medicine; https://doi.org/10.1186/s12967-025-06770-2)
Gastric Cancer Neoadjuvant Immunotherapy
Sixteen gastric cancer patients were profiled via RNA-seq and an Olink proteomics panel before and after neoadjuvant therapy (immunotherapy + chemotherapy). Differential proteins included CD8A and PGF. CD8A showed excellent prognostic power (AUC ~1.00), and PGF was associated with poorer treatment effect. (Zhang et al., 2025. BMC Cancer https://doi.org/10.1186/s12885-025-14046-7 )
Key Principles & Strategies
Baseline vs Dynamic Biomarkers
Baseline levels (pre-treatment) of certain proteins often predict likely response. Changes post-treatment can refine understanding of mechanism or resistance. Studies above used both.
Model Integration of Multiple Data Types
Combining protein biomarkers with immune cell profiling (CyTOF), gene-expression, or clinical variables improves stratification. Feature sets drawn from both soluble mediators (cytokines, growth factors) and cell subset frequencies result in stronger models than either alone.
Selection of Panels That Capture Immune-Relevant Biology
Panels should include cytokines, chemokines, receptors, and other immune modulators. For example, Olink 92-plex immune panels or broader NPX-based panels that include immune modules.
Statistical Rigor
Use ROC/AUC, cross-validation, independent validation cohorts. Beware overfitting, especially with many proteins. Limit the number of features or use penalised regression / machine learning to avoid spurious associations.
Recommendations for Research Teams
Define Clear Endpoints / Response Metrics
Even in non-clinical settings, define what "treatment response" means (e.g., biomarker modulation, tumour growth in preclinical models, immune cell activation) so that the predictive signature is well anchored.
Standardize Sample Handling & Timing
Baseline sample collection, consistent pre-analytic protocol (serum vs plasma, storage time, freeze-thaw), and matching time points are crucial. Differences in immune signaling are subtle and sensitive to variability.
Plan for Validation
After discovery in one cohort, aim to test the signature in an independent or blinded dataset to assess generalisation.
Consider Biological Mechanism
Features that also make sense mechanistically (e.g., known involvement in immune activation, tumour suppression, myeloid suppression) tend to have more robustness. Use cytokine / immune panels that include proteins with known roles in cancer immunology.
Large-Scale & Longitudinal Studies: Population Serum Proteomics & Olink
Longitudinal and large-scale serum/plasma proteomics is a potent tool in oncology-related research. These studies allow detection of early changes in protein expression, risk stratification over time, and the identification of novel biomarker candidates in large, diverse populations. Below are major examples, technical insights, and recommendations.
Major Studies & Findings
UK Biobank & Proteogenomics Projects
Olink's population-scale proteogenomics initiatives (e.g., UK Biobank Plasma Proteomics Project) have measured ~3,000 plasma proteins in over 50,000 participants. These datasets are enabling the mapping of genotype–protein relationships (protein quantitative trait loci, pQTLs), discovering rare variant effects, and associating protein levels with disease risk.
Wellness Cohort Study (Magis et al., 2020)
In a longitudinal wellness cohort, researchers used Olink proteomics to profile healthy individuals over time. They identified proteins (e.g. CALCA, DLK1) whose expression changed months to years prior to metastasis or cancer diagnosis. For instance, CALCA and DLK1 were outliers in pancreatic cancer more than a year before diagnosis.
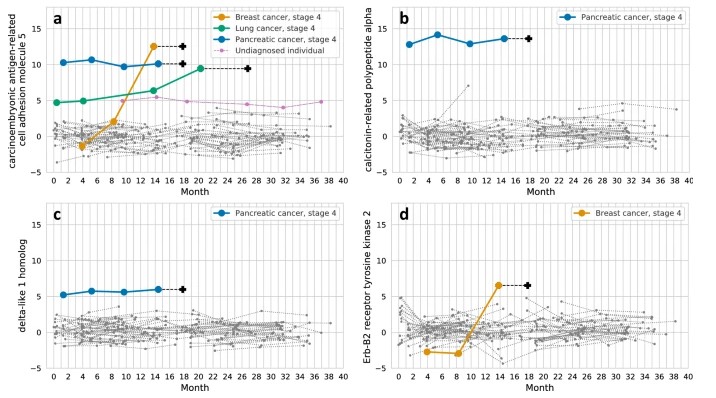 Fig. 2 Longitudinal trajectories of selected outlier proteins across multiple cancer types in individuals.
Fig. 2 Longitudinal trajectories of selected outlier proteins across multiple cancer types in individuals.
Novelna's Pan-Cancer Plasma Test (Explore-3072 Panel)
Novelna Inc. profiled >3,000 proteins in plasma from individuals with early-stage solid tumors (18 different tumor types) and healthy controls. They derived sex-specific 10-protein panels with high sensitivity (93% in men; 84% in women) for cancer detection at very high specificity. Also, tissue-of-origin models achieved ~80% accuracy.
Serum Proteomics & Immune-Oncology Across Ancestries (Minas et al., 2022)
A study of ~3,000 men (cases and controls) from Ghana, African-American, and European American populations measured 82 immune-oncology proteins via Olink. They observed that signatures of suppression of tumour immunity and chemotaxis were elevated in men of West African ancestry, correlating with more aggressive prostate cancer.
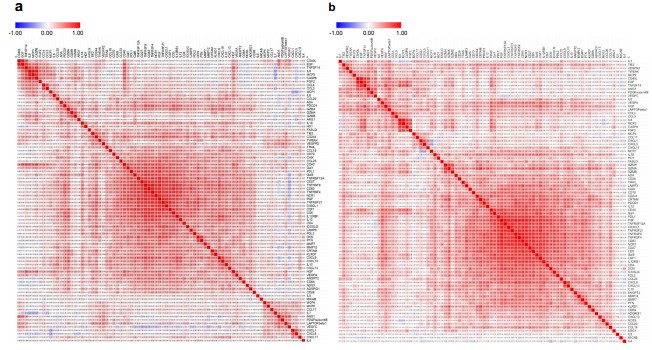 Fig. 3 Correlation matrix presenting Pearson pairwise correlations for each of the 82 serum protein pairs in African American men.
Fig. 3 Correlation matrix presenting Pearson pairwise correlations for each of the 82 serum protein pairs in African American men.
Strengths & Technical Insights
Temporal Sampling Enables Pre-Diagnosis Discovery
Longitudinal sampling (well-before diagnosis) helps identify changes in protein levels that could serve as early risk markers, reducing lead-time bias. The wellness cohort (Magis et al.) is a prime example.
Large Sample Size Improves Generalizability
Studies with tens of thousands of participants (UK Biobank) reduce overfitting, increase diversity of covariates, and enable stratification by demographic variables (age, sex, ethnicity).
High Plex & Multiplex Panels
Use of high‐plex exploratory panels (e.g., Olink Explore-3072) allows detection of both low-abundance and high-abundance proteins, across many pathways. This enables broad discovery while maintaining statistical power.
Integration with Genetic/EHR Data
By combining proteomics with genotype (pQTL analyses) and extensive phenotypic / health-record data (as in UK Biobank), researchers can identify causal associations and adjust for confounders.
Challenges and Limitations
Preanalytic Variability
Sample collection timing, storage, handling, freeze-thaw events, and sample matrix (serum vs plasma) can introduce noise. Especially in large cohorts, when protocols vary across sites. Magis et al. highlighted some of these issues.
Statistical and Multiple Testing Burden
With thousands of proteins measured, false discovery rates must be carefully managed. Overfitting risk in models derived from many features without independent validation remains high.
Heterogeneity in Population & Biological Confounders
Differences in age, sex, comorbidities, ethnicity, environmental exposures can influence baseline protein levels. Adjusting for these is essential. The Minas et al. study showed ancestry explained substantial variance in immune-oncology proteins.
Best Practices & Recommendations for Research Teams
Design Prospective Sampling with Repeated Measures
If possible, collect serial samples well before any known tumour presentation, at multiple timepoints. This helps track trajectories, not just snapshots.
Ensure Large, Well-Characterised Cohorts
Demographics, lifestyle, medical background should be recorded to account for confounders. Otherwise signals may reflect environmental or demographic differences rather than early disease biology.
Use High-Plex Exploratory Panels First, Then Validate
Start broad (e.g., Explore-3072) to detect candidate biomarkers. Then narrow down with focused panels (e.g., cytokine panels, targeted 96-plex) for verification in independent cohorts.
Integrate with Genomic / Other Omics Data
Incorporate pQTLs, genotype data, gene expression, or epigenetic data when possible. Helps distinguish cis vs trans effects, and strengthens biological plausibility.
Rigorous Statistical Workflows
Cross-validation, external validation, correction for multiple comparisons, accounting for preanalytic and demographic covariates.
Transparent Reporting
Publish performance metrics (AUC, sensitivity, specificity), explain sample handling, outliers, exclusion criteria. Make data or summary metrics accessible (if allowed by ethics).
Challenges, Limitations & Best Practices
| Category | Key Challenges / Limitations | Best Practices / Mitigation Strategies |
| Pre-analytical Variables |
|
|
| Assay Precision, Reproducibility & Detection Limits |
|
|
| Statistical / Design Limitations |
|
|
| Sample Size & Population Diversity |
|
|
| Panel & Assay Limitations |
|
|
| Data Processing & Interpretation |
|
|
| Logistics & Cost Considerations |
|
|
How to Integrate Olink in Your Oncology/Biomarker Discovery Pipeline
Bridging from discovery to validated biomarker candidates demands planning. In this section, I'll walk through a typical pipeline using Olink proteomics for non-clinical oncology research, with tips to maximise reproducibility and discovery power.
Pipeline Steps
Define Clear Research Goals
- What is your primary question? Early detection, immune profiling, prediction of response in preclinical models, etc.
- Decide whether you are exploring broadly (hypothesis generation) vs verifying a small set of proteins.
Choose Appropriate Olink Panels
- For wide discovery, use large multiplex panels (e.g. Olink Explore-3072) to cover many pathways.
- If you're focused on immune / cytokine biology, select the Olink Cytokine Panel or immune-module panels.
- Consider panels validated for serum or plasma depending on sample type.
Sample Collection & Preanalytical Standardisation
- Standardise blood-sample handling: time to centrifugation, storage temperature, freeze/thaw cycles.
- Choose serum or plasma, and stick with one for consistency.
- Record metadata: donor age, sex, comorbidities, time of day, fasting status etc.
Pilot Study & Feasibility
- Run a small subset to assess detectability, missing values, variance.
- Identify batch effects early, test replicates.
Discovery Phase
- Use exploratory panels and broad sampling (e.g. longitudinal or cross-sectional depending on goal).
- Use statistical methods suited for high-plex data: correction for multiple testing, feature selection, cross-validation.
Validation Phase
- Narrow candidate list, verify in independent cohort(s).
- Use focused Olink panels or custom assays.
- Validate with orthogonal methods if possible (e.g. ELISA, targeted mass spec).
Bioinformatics & Data Integration
- Correct for confounders: age, sex, ethnicity, sample handling, batch.
- Incorporate other omics when available (e.g. transcriptomics, genomics) for mechanistic insight.
- Use robust visualisation and statistical modelling (ROC curves, AUC, multi-feature models).
Interpretation & Reporting
- Report performance metrics (e.g., sensitivity, specificity, AUC) with confidence intervals.
- Be transparent about sample size, inclusion/exclusion criteria, missing data.
- Use NPX units, note limits of detection, reproducibility, recommend if absolute quantification used.
Case Study Spotlight: Next-Generation Plasma Test for Multi-Cancer Early Detection
To illustrate how Olink proteomics can power non-clinical biomarker discovery at scale, consider the recent multi-cancer early detection study by Novelna Inc. using the Olink Explore-3072 panel. (Budnik et al., 2024)
Study Design & Key Findings
Cohort & Sampling: Plasma samples collected from ≈ 440 individuals, including healthy controls and patients with 18 different early-stage solid tumours.
Assay: Used Olink Explore-3072 high-throughput proteomics to measure >3,000 proteins, both high- and low-abundance, in each sample.
Sex-specific Models: Developed separate biomarker panels for males vs females (10 proteins each). At high specificity (~99%), they detected 93% of cancers in men and 84% in women.
Tissue-of-Origin Prediction: A larger multi-protein model (≈150 proteins) was able to correctly classify tissue of origin in > 80% of cases.
Technical Strengths & Learnings
- High Sensitivity & Specificity Trade-offs: The sex-specific small panels show very high performance in early-stage cancers when using stringent specificity thresholds. Illustrates that even with relatively few proteins, careful selection yields strong predictive power.
- Importance of Low-Abundance Proteins: Many discriminating proteins were in the low-concentration part of the plasma proteome, underscoring the utility of Olink's sensitivity in detecting cytokines / rare secreted proteins.
- Model Generalisability: The study used independent control vs tumour samples, but further validation in external cohorts will be important to test broader utility.
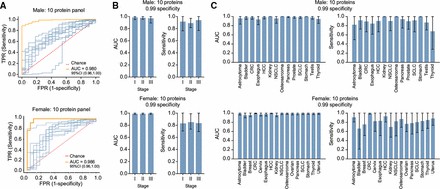 Fig 4 Performance of the detection panel.
Fig 4 Performance of the detection panel.
Relevance for Research Teams
This case demonstrates that:
- Large exploratory panels (e.g. Explore-3072) allow discovery of candidate biomarkers for both detection and origin prediction.
- Building sex- or demographic-specific models may improve accuracy and reduce bias.
- Even "research-use-only" applications (non-clinical) benefit greatly from rigorous statistical design, high specificity cutoffs, and focus on low-abundance protein detection.
Conclusion
Olink proteomics has emerged as a versatile and powerful tool for non-clinical oncology research. Across the sections above, we've seen how its combination of high sensitivity, small sample volumes, and multiplex cytokine / broad exploratory panels enables:
- discovery of early markers long before overt disease
- detailed immune and tumour microenvironment signalling
- prediction of response in preclinical or translational models
- robust findings in large, longitudinal, or population-scale cohorts
At the same time, we've noted the technical and statistical challenges: sample handling, assay reproducibility, panel selection, model overfitting, and the need for validation. Addressing these proactively in your study design can greatly increase confidence in findings and make them useful in your internal pipelines.
Why Olink Proteomics Can Be a Game-Changer for Your Research
- Trustworthy quantification across a wide dynamic range with precision even for low-abundance cytokines.
- Scalability from discovery to focused panels, allowing you to start with large exploratory datasets (e.g., thousands of proteins), then narrow to targeted panels. Olink's product portfolio supports that (Explore, Reveal, Target, Focus).
- Integration with genomics / pQTLs in population studies, which enhances biological insight and strengthens biomarker hypotheses. SCALLOP / UK Biobank-PPP findings show the added value as cohort sizes increase.
What You Should Do Next
If your team is planning or running non-clinical oncology biomarker discovery, here are concrete next steps:
Perform a pilot study using Olink exploratory/high-plex panels (e.g. Explore-3072 or Reveal) to identify candidate proteins in your samples and test reproducibility.
Ensure rigorous handling of pre-analytical variables: sample type, processing time, storage, metadata. This can be as important as the assay itself.
Design your statistical workflow ahead of time: include cross-validation, external or independent cohorts, feature selection, and correction for multiple testing.
Validate top candidates in a focused panel (Target or custom), potentially with orthogonal methods (e.g. ELISA, targeted mass spec) to confirm findings.
Leverage external datasets (e.g. UK Biobank, population cohorts) and multi-omics (genomics, transcriptomics) to add mechanistic and generalisable support.
References
- Davies, Michael P.A. et al.Plasma protein biomarkers for early prediction of lung cancer.eBioMedicine, Volume 93, 104686
- Enroth, S., Berggrund, M., Lycke, M. et al. High throughput proteomics identifies a high-accuracy 11 plasma protein biomarker signature for ovarian cancer. Commun Biol 2, 221 (2019). https://doi.org/10.1038/s42003-019-0464-9
- Xiao C, Wu H, Long J, You F, Li X. Olink Profiling of Intestinal Tissue Identifies Novel Biomarkers For Colorectal Cancer. J Proteome Res. 2025 Feb 7;24(2):599-611. doi: 10.1021/acs.jproteome.4c00728. Epub 2025 Jan 5. PMID: 39757570; PMCID: PMC11812010.
- Zhang, C., Wang, T., Yuan, J. et al. Potential predictive value of CD8A and PGF protein expression in gastric cancer patients treated with neoadjuvant immunotherapy. BMC Cancer 25, 674 (2025). https://doi.org/10.1186/s12885-025-14046-7
- Budnik B, Amirkhani H, Forouzanfar MH, Afshin A. Novel proteomics-based plasma test for early detection of multiple cancers in the general population. BMJ Oncol. 2024 Jan 9;3(1):e000073. doi: 10.1136/bmjonc-2023-000073. PMID: 39886137; PMCID: PMC11235013.
- Minas, T.Z., Candia, J., Dorsey, T.H. et al. Serum proteomics links suppression of tumor immunity to ancestry and lethal prostate cancer. Nat Commun 13, 1759 (2022). https://doi.org/10.1038/s41467-022-29235-2
- Budnik B, Amirkhani H, Forouzanfar MH, Afshin A. Novel proteomics-based plasma test for early detection of multiple cancers in the general population. BMJ Oncology. 2024;3:e000073. https://doi.org/10.1136/bmjonc-2023-000073




